| tags:macos tips&tricks ai categories:computing
Whisperで文字起こし
ちょっと色々と気になっているAI関連、 フォローしているビットコインナーさんの記事をみて結構使えるとのことで、 ブログであげているYutubeの文字起こしに使えそうなので、Whisper をインストールして試してみました。
OpenAI Whisper Transcription Testing : https://blog.lopp.net/openai-whisper-transcription-testing/
Python
MacOSにインストール済みのPythonはバージョン(3.8.9)が古いのでアップデートします。 Brewが必要なのでインストールしていない方は、便利なパッケージマネージャーなので是非是非。
ターミナルでインストールの作業、Whisperの利用を行います。
% brew install python
Python has been installed as
/opt/homebrew/bin/python3
Unversioned symlinks `python`, `python-config`, `pip` etc. pointing to
`python3`, `python3-config`, `pip3` etc., respectively, have been installed into
/opt/homebrew/opt/python@3.10/libexec/bin
You can install Python packages with
pip3 install <package>
They will install into the site-package directory
/opt/homebrew/lib/python3.10/site-packages
tkinter is no longer included with this formula, but it is available separately:
brew install python-tk@3.10
See: https://docs.brew.sh/Homebrew-and-Python
%
インストール後は一度ターミナルを環境設定の再読み込みのため、ターミナルを再起動します(コマンドもあったが忘れた。)。
Whisperのインストール
事前に必要なソフトウェアをインストールします。
$ brew install ffmpeg
$ *brew install rust
依存するソフトウェアも割とたくさんインストールされます。 rustはエラーが出たらインストールを。(問題が出るとか出ないとか、私の環境では既にインストール済みだったので検証できず)
そしてメインのWhisperをインストールします。 で、pipのバージョンが古いとインストール後に注意が出たので、事前にアップデートしておくのが良いです。
% python3 -m pip install --upgrade pip
% pip3 install git+https://github.com/openai/whisper.git
先々のアップグレードは以下のコマンドより行います。
% pip3 install --upgrade --no-deps --force-reinstall git+https://github.com/openai/whisper.git
で、あっさりとインストールできました。
で、お次は利用法、YouTubeより音声データーをとってきて文字起こしをします。
Youtubeビデオの文字起こし
まず、youtube-dl
というソフトウェアを使って、YouTubeの動画から音声ファイをダウンロードします。
https://github.com/ytdl-org/youtube-dl/blob/master/README.md
アプリのインストールはBrewを使って一発です。
% brew install youtube-dl
作業の流れはファイルのダウンロード、そして文字起こしと至ってシンプルです。 YouTubeのURLは短いもので無いとエラーが出ましたので、そのときは画面から右クリックでURLをコピーしてください。
% youtube-dl --extract-audio --audio-format mp3 <YouTube video URL>
% whisper ./<audio filename>.mp3 --model medium
で、実際の画面はこんな感じで、初回文字起こし時に、データーセットのダウンロードが行われます。 mediumのサイズで1.4GBとちょっと大きいです。12分半の音声処理に28分かかりました。
% youtube-dl --extract-audio --audio-format mp3 https://youtu.be/oHJN_iMvkJg
[youtube] oHJN_iMvkJg: Downloading webpage
[youtube] oHJN_iMvkJg: Downloading MPD manifest
[download] Destination: Looking back to move forward - Gerson Martinez - Adopting Bitcoin Day 1 - Bitfinex Stage-oHJN_iMvkJg.m4a
[download] 100% of 11.70MiB in 03:58
[ffmpeg] Correcting container in "Looking back to move forward - Gerson Martinez - Adopting Bitcoin Day 1 - Bitfinex Stage-oHJN_iMvkJg.m4a"
[ffmpeg] Destination: Looking back to move forward - Gerson Martinez - Adopting Bitcoin Day 1 - Bitfinex Stage-oHJN_iMvkJg.mp3
Deleting original file Looking back to move forward - Gerson Martinez - Adopting Bitcoin Day 1 - Bitfinex Stage-oHJN_iMvkJg.m4a (pass -k to keep)
% whisper ./FILE.mp3 --model medium
100%|█████████████████████████████████████| 1.42G/1.42G [10:22<00:00, 2.46MiB/s]
/opt/homebrew/lib/python3.10/site-packages/whisper/transcribe.py:78: UserWarning: FP16 is not supported on CPU; using FP32 instead
warnings.warn("FP16 is not supported on CPU; using FP32 instead")
Detecting language using up to the first 30 seconds. Use `--language` to specify the language
Detected language: English
[00:00.000 --> 00:01.160] Gee, are you guys ready?
[00:01.160 --> 00:02.760] Wasn't that inspirational?
[12:25.860 --> 12:37.860] Thank you.
%
そして、
FILE.mp3.srt, FILE.mp3.txt, FILE.mp3.vttの3つのファイルが書き出されます。
*.srtは動画の字幕ファイルかな。もう一つ行ってみましたが、大体2倍の時間がかかるみたいです。
CPU・GPUの負荷はこんな感じです。ファンは回りませんでした。GPUはほとんど使ってない感じ、、 肝心の正確度はかなり高いです。さらっ〜とみた感じでは、間違いは発見できず。
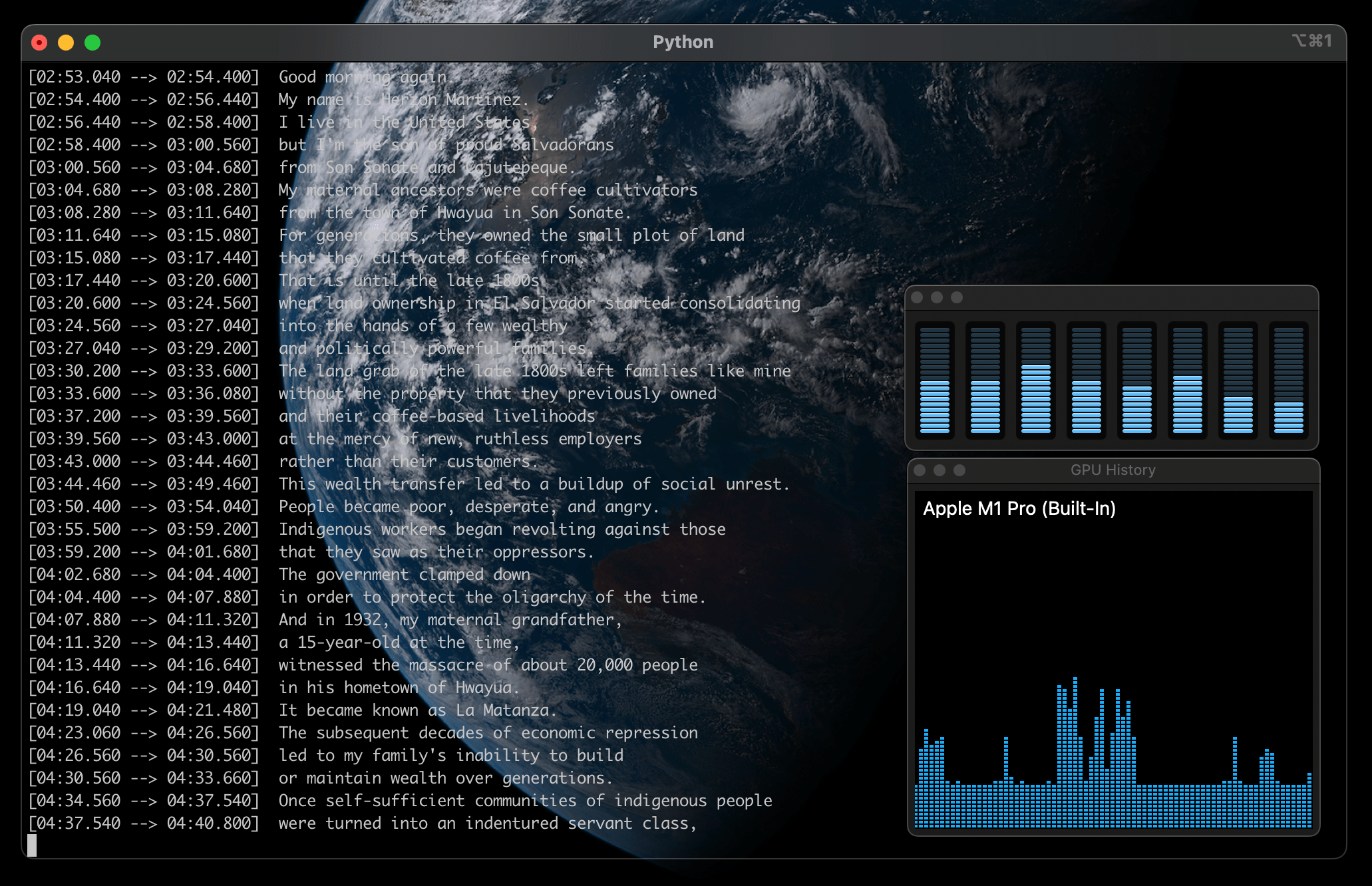
つぎは、StableDiffusionで挿絵でも入れようかなと思ってます。 いやぁ、これは仕事がなくなるわな。。
おまけ
試してはいませんが、日本語の文字起こしもできます。
日本語の文字起こしは言語を設定、--language Japanese を追加
% whisper japanese.wav --language Japanese
英語に翻訳したいときは、さらに --task translateを追加します。逆方向もできるのかな。。
% whisper japanese.wav --language Japanese --task translate
翻訳の精度はわからず。
参照:
- https://github.com/openai/whisper
- Struggling to get Whisper installed on an M1 Macbook Pro : https://github.com/openai/whisper/discussions/403

{kind=link}